







Respond to the speed that business demands
The effective use of big data has been a business challenge of late. Thus, there are increasing expectations for computing systems that can process a large amount of data faster and more efficiently. My field of specialty is parallel and distributed computing. A familiar concept is that of the development of supercomputers. The challenge here is to speed up computation, and my research heavily focuses on accelerating computer processing capabilities.What are the advantages of speeding up a computer? Firstly, a fast computing speed makes it possible to conduct a deeper analysis within the same amount of time. As speed is vital, particularly in business decision making, the priority has been given to speed over highly accurate analysis. Furthermore, handling a huge amount of data is expected to lead to new business opportunities. In the field of computer science, we are engaged in researching methods for handling enormous amounts of diverse sets of data with speed and efficiency, and in accordance with social needs.
The behavior of big data, as a program, differs considerably from the programs that have been handled by supercomputers. Because of this, new strategies that are different from conventional strategies are required for speeding up computation. In fact, parallel and distributed computing has not been very effective in handling big data. It almost seems that even this topic has been avoided among researchers. For example, once there was a perception that supercomputers were not suitable for the field of gene analysis. However, around 2004, IBM developed the world’s fastest supercomputer, called the “Blue Gene,” which demonstrated superior performance in gene analysis. Since then, research on life sciences including gene analysis has advanced rapidly. This example suggests that it is still premature to conclude that parallel and distributed computing is not suitable for big data analysis. As a computer scientist, I want to plan out a thorough strategy especially in the field of data stream analysis(*1). I am first planning to clarify the characteristics for modeling, and then I will consider how to optimize the strategy, the CPU, and the computer architecture.
Establishing a dedicated benchmark is imperative

“Discussions on big data have just begun,” says Associate Professor Akioka
At the same time, creating a benchmark program for big data is another task. Although LINPACK is well known as a benchmark program used for ranking the world’s high-speed computers, the behavior of big data applications is not reflected in the current benchmarking program, and thus my next task is to create a new benchmark.
A new benchmarking program should define the mechanism of speeding up big data processing – and this will serve as a milestone for development. As both the hardware and software can be developed with an eye toward the same goal, the development will be accelerated. To propose such a benchmark is my immediate goal. It is not an easy task. Although LINPACK is recognized as the world standard now, it took 5 to 10 years before it became widely used globally after the earliest version was released. And it has been updated repeatedly over the last 30 years since it was first released. In this sense, the creation of a benchmark for big data applications will be the work of a lifetime. As benchmarks are used by people, they will thus continue to go through versions by incorporating the opinions of the users. In any event, it is important to release a new benchmark.
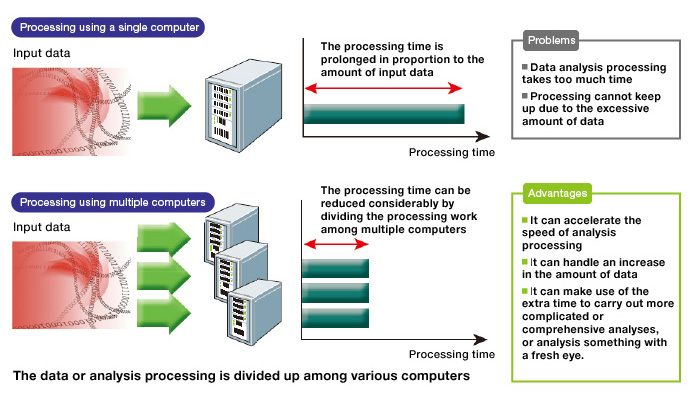

A computer is just a tool. It is not yet a tool to force people to do the work.
Toward advancements in both hardware and software
In the field of big data, what concerns me most is that those who develop analytical methods for big data and write programs are cutting down on their sleep in order to work hard, on the premise that the available computers are not suitable for big data. A computer is no more than a tool, and if they are puzzling over how to use the computer, we are still a long way from reaching our goal.Since this problem, in some ways, unnecessarily hampers research on big data, dealing with this problem should be a top priority. When this problem is solved and the specialists who develop these methods know that they have more freedom, it will enable them to dedicate themselves entirely to the performance of their primary work, that is, the analysis of big data and the retrieval of useful information from it rather than being forced to write programs.
I also think we should form a research community and work on this development as a group. Even if the hardware is developed, if that hardware is difficult to use with the software, we cannot expect to promote its use. Good hardware makes it possible to produce programs and software that can make good use of it. It is essential to be able to use the hardware and software as a set.
Fortunately, experts in a variety of research fields are gathering together at the School of Interdisciplinary Mathematical Sciences, Meiji University. By exchanging information across disciplines, we have an advantage in reaffirming the positioning of our research from time to time. As an application, big data is not mature enough for us to determine a single direction towards a solution. This means this field can be developed multi-dimensionally. Although experts are apt to go in directions biased towards their own field, the interdisciplinary school provides them with an opportunity to reexamine their own research objectively.
Leave simple tasks to the computer
I will continue to work on the development of faster and more efficient technology based on parallel and distributed computing. The computer is only a tool, and ideally people should concentrate on creative tasks, and leave other simple tasks to the computer. My dream computer can accept any program and rewrite it if needed, run it by choosing the fastest strategy and environment, and even return the results. This dream may not come true even within 100 years, but I will continue my research, dreaming about such a world.
(*1) Data stream analysis
This is a method in which a large amount of real-world generated data is processed in a time series manner, and then totaled and analyzed. The conventional processing method in which the server accumulates and stores data causes a time lag. On the other hand, data stream analysis enables real time state monitoring and decision-making based on newer data, and is expected to expand business opportunities in a variety of fields.
Profile
Associate Professor, Department of Network Design, School of Interdisciplinary Mathematical SciencesResearch interest: Network Design, Parallel and Distributed Computing. Strives to increase the speed and sophistication of applications such as big data analysis.
Completed the doctoral program without a degree, Department of Computer Science, Faculty of Science and Engineering, Waseda University
Ph.D. in Computer Science, Waseda University



